

Pattern
recognition
(HOW TO BUILD AN EFFICIENT PATTERN RECOGNITION APPLICATION ?)
Keywords : how to build an efficient pattern recognition application, tutorial, pattern recognition, vision, image processing, signal processing, data analysis, multisensors signature, signature, statistics, bayesian networks, decision trees, eigen vectors discrimination methods, artificial neural networks, fuzzy logic, fuzzy decision arrays, genetic classifiers, vector learning machines, expert systems, case based reasoning, rough data, preprocessing, descriptor, shape descriptor, fourier descriptor, descriptor extraction, classification, postprocessing, recognized pattern, qualitative variable with N modalities, unrecognized pattern, confidence, methodology, AGENDA, functional description of a pattern recognition system, factors of variation, filtering factors of variations, agenda graph, unvariant with, learning data base, tuning data base, test data base, design plans, eigen vectors, reverse engineering of pattern recognition systems
Written by Gerard YAHIAOUI and Pierre DA SILVA DIAS, main founders of the applied maths research company NEXYAD, © NEXYAD, all rights reserved : for any question, please CONTACT
Reproduction of partial or complete content of this page is authorized ONLY if "source : NEXYAD http://www.nexyad.com" is clearly mentionned.
This tutorial was written for students or engineers that wish to understand main hypothesis, ideas, and methodologies of pattern recognition applications.
Vocabulary
(HOW TO BUILD AN EFFICIENT PATTERN RECOGNITION APPLICATION ?)
Keywords : how to build an efficient pattern recognition application, tutorial, pattern recognition, vision, image processing, signal processing, data analysis, multisensors signature, signature, statistics, bayesian networks, decision trees, eigen vectors discrimination methods, artificial neural networks, fuzzy logic, fuzzy decision arrays, genetic classifiers, vector learning machines, expert systems, case based reasoning, rough data, preprocessing, descriptor, shape descriptor, fourier descriptor, descriptor extraction, classification, postprocessing, recognized pattern, qualitative variable with N modalities, unrecognized pattern, confidence, methodology, AGENDA, functional description of a pattern recognition system, factors of variation, filtering factors of variations, agenda graph, unvariant with, learning data base, tuning data base, test data base, design plans, eigen vectors, reverse engineering of pattern recognition systems
Written by Gerard YAHIAOUI and Pierre DA SILVA DIAS, main founders of the applied maths research company NEXYAD, © NEXYAD, all rights reserved : for any question, please CONTACT
Reproduction of partial or complete content of this page is authorized ONLY if "source : NEXYAD http://www.nexyad.com" is clearly mentionned.
This tutorial was written for students or engineers that wish to understand main hypothesis, ideas, and methodologies of pattern recognition applications.
Vocabulary
Pattern
recognition is a field of application for many applied maths methods
such as statistics, bayesian networks, decision trees, eigen vector
based discrimination methods ("classical data analysis"), artificial
neural networks, fuzzy decision arrays, genetic classifiers, vector
learning machines, expert systems, case based reasoning, ...
It may also be applied to "shapes" that are defined in many ways :
- images : example : optical characters recognition (OCR)
- signals : example : speech recognition
- data : example : answers to a questionnary
- multisensors signatures : example : biometric applications
These several physical sources of data/signals/images make "preprocessings" come from many applied maths techniques such as vision/image processing, signal processing, data analysis, ...
Because every applied maths domain has its own vocabulary, it is important that we choose a vocabulary for pattern recognition that will not be influenced by the techniques. We also have to give a clear definition of 'pattern recognition'. Even if some readers may disagree with our definitions, they will be usefull for our purpose : giving a very short description of main difficulties, methodologies, and tricks not to stay trapped in.
We will consider that a pattern recognition system can be described with the following regular synoptic :
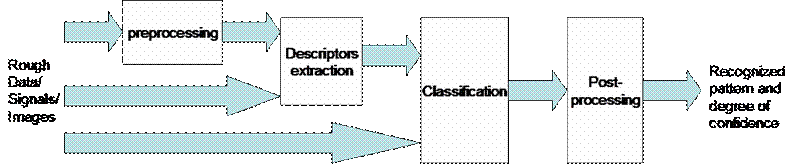
Rough data / rough signals / rough images directly come from sensors or measurement systems.
Preprocessing elements are :
- transforms (ex : Fourier Transform)
- normalisations
- denoising
- ...
Descriptors extraction system builds a "signature" from preprocessed and/or rough data. The "signature" is a set of data that are supposed to contain useful and "easy to use" information for classification. Elements of the signature may be :
- shape parameters (ex : Fourier descriptors, shape descriptors, ...),
- a selected part of preprocessed and/or rough data,
- scores (from scoring methods),
- ...
Classification system takes a set of descriptors and/or rough data and evaluates which "class" it should belong to.
One also could say that the output of the Classification system is a qualitative variable with N modalities. Every modality of this variable is called a "class".
There are many Classification techniques such as :
- classical statistics based methods,
- bayesian networks,
- decision trees,
- eigen vectors based discrimination methods,
- artificial neural networks,
- fuzzy decision arrays,
- genetic classifiers,
- vector learning machines,
- expert systems,
- case based reasoning, ...
- ...
Some classification techniques can tune automatically their parameters in order to optimize their performance on a sample of data (we will talk about "supervised learning", even if classical data analysis techniques, for instance, never use such a vocabulary).
Some classification techniques may use the knowledge of experts. We will talk about knowledge based systems.
Postprocessing system allows :
- to estimate the confidence of the classification
- to re evaluate the class taking into account the risk attached to misclassification
- to add a class number (N+1) that says "unrecognized"
The most frequently asked question is "how to build an efficient pattern recognition system ?".
Because the "heart" of such a recognition pattern system is the "classification" system, one often considers that the first task is to choose a classification technique : "should i use neural networks ? Bayesian networks, ...".
This is the wrong way.
The first task is to choose a global architecture : if one uses heavy preprocessings and smart descriptors extractions, classification may become easier. On the opposite, classification from rough data may need to choose a powerful classification technique. The balance between preprocessings, descriptors extraction, and classification complexity is the first point to check. There doesn't exist a unique solution : many solutions may lead to acceptable results.
There is a methodology that helps to build efficient solutions and to evaluate their viability before the development : the AGENDA methodology (see further and check references).
How to build an efficient pattern recognition application : the AGENDA methodology
The AGENDA methodology proposes to write a functional analysis of the pattern regognition system (before starting any development). From this functional analysis, one can choose technical solutions, linking every technical choice to a functional need. This "classical" way of working (classical for regular industrial projects ... but not for pattern recognition projects) allows :
- to share the knowledge of several experts on the rough data
- to choose functional options before any technical choice that could disable a functionality
- to brainstorm on algorithms choice
- to guarantee traceability of every technical choice
- to re use solutions from a project to another if some functionalities are the same
- to test separately every module
- to help for maintenance and further evolutions development
- to communicate quickly with other searchers and engineers (every choice has an explicit reason)
AGENDA proposes a special way of describing functionalities for a pattern recognition system. This way is general and can be applied to a big range of applications. The idea is to consider the known causes of variations of the input vector :
example : character recognition : Known causes of variations are :
- small rotation of the character
- translation
- thickness of lines
- style (font)
- colour of printing
- name of the character (1, a, 2, b, c, ...)
- ...
This causes of variations generate together a combination of cases that leads to a very big number of different characters. That is why pattern recognition is a complicated task : only a few causes of the input vector variations should lead to a variation of the output (ex : name of the character), most causes of variations of the input vector shouldn't change the output (ex : thickness, rotation, translation, ...)
It means that the pattern recognition system can be seen as a "filter" on factors of variations.
This leads to a very simple way of describing the expected functionalities of a pattern recognition system : one should just choose if a factor is to be filtered or not : example :
- small rotation of the character
- translation
- thickness of lines
- style (font)
- colour of printing
- name of the character (1, a, 2, b, c, ...)
- ...
means "usefull" factor of variation : "not to be
filtered"
means
"to be filtered"
And every
factor should be linked to a technical solution
"invariant with this
cause of variation".
Example :

Red links are a memory of the goal of every technical choice.
If one cannot find a solution for some factors of variations, then one still can use a "learning" classification system : example :
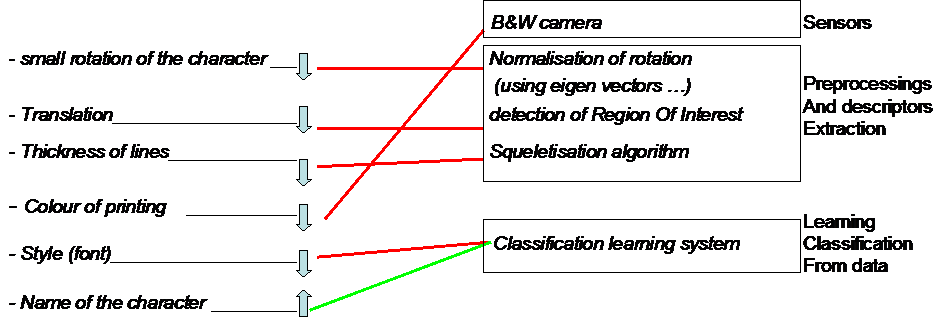
It becomes obvious, looking at such an "AGENDA graph", that there exist many solutions : many technical items may have the same "unvariant with" functionality; other sensors may lead to a simpler solution; ...
But this AGENDA Graph can also bring more information :
- every link has a cost : computing time, ...
- intuitively, one can understand that a graph with every link pointing to the classification learning system would need more examples to get tuned than the above graph (example : no preprocessing, no descriptors extraction, and rough data directly into a neural network ...). The idea is to use the design plans in order to build the data base : orthogonal design plans (of the set of factors that point on the learning system) should be considered as a simple way of building this data base.This data base is needed for :
- getting a learning data base (if classification is automatically tuned from data) or a tuning data base (if classification is tuned
by hand),
- getting a test data base : to evaluate performance of the classification system on examples that were not used to tune it.
Although there is a deterministic and simple way of building a relevant data base, one needs to cut this data base into 2 parts in order to get two sub-data bases : the learning and the test ones. This is made by using two fractional sub design plans.
Then, it is important to verify that the 2 data bases are representations of the same statistical phenomenon in the variables space (preprocessed data and descriptors) : mean values, standard deviations, and N first eigen vectors must be the same.
At this point, a classification technique is carefully picked. Criteria of choice are :
- do i have an explicit expertise for classifying examples (is yes, knowledge based systems such as fuzzy decision arrays may be a good solution : they are usually tuned "by hand"; if not, learning based methods, automatically tuned from data, such as neural networks or bayesian networks may be a good solution).
- do i need an explicit explanation of the result (if yes, "black boxes" methods are forbidden ...),
- do i have a software that lets me apply classification techniques (or can i buy one ? develop one ? ...),
There are often several classification techniques that fit into criteria and it is a good thing to test several approches in order to know which part of the result is a "method" effect.
Once the classification system is tuned, it is time to build the post processing system : th aim of this system is to interpret quantitative partial informations of the classification system in order to give to the final result a confidence. Lack of confidence should lead to a new output (never given by a classification system) : "unknown" or "unrecognized".
Methods for confidence estimation are different for every classification method, but main ideas are :
- choose a measure of confidence for the selected class,
- choose a measure of hesitation (comparing confidence for the selected class to confidence for the other classes)
- use a decision method from this measures.
Once the pattern recognition system is available, tests often show cases of misclassification. Analysis of those cases allows to upgrade AGENDA graphs : some factors of variations are added, new preprocessings/descriptors can be picked, and the data base can be upgraded.
This incremental way of building the system is a guaranty of maintenability : indeed, industrial applications often need evolutions among time (new functionalities, new classes, ...). The AGENDA graphs can be considered then as a memory of the engineering process, allowing a very quick reverse engineering for maintenance and upgrades.
It may also be applied to "shapes" that are defined in many ways :
- images : example : optical characters recognition (OCR)
- signals : example : speech recognition
- data : example : answers to a questionnary
- multisensors signatures : example : biometric applications
These several physical sources of data/signals/images make "preprocessings" come from many applied maths techniques such as vision/image processing, signal processing, data analysis, ...
Because every applied maths domain has its own vocabulary, it is important that we choose a vocabulary for pattern recognition that will not be influenced by the techniques. We also have to give a clear definition of 'pattern recognition'. Even if some readers may disagree with our definitions, they will be usefull for our purpose : giving a very short description of main difficulties, methodologies, and tricks not to stay trapped in.
We will consider that a pattern recognition system can be described with the following regular synoptic :
Rough data / rough signals / rough images directly come from sensors or measurement systems.
Preprocessing elements are :
- transforms (ex : Fourier Transform)
- normalisations
- denoising
- ...
Descriptors extraction system builds a "signature" from preprocessed and/or rough data. The "signature" is a set of data that are supposed to contain useful and "easy to use" information for classification. Elements of the signature may be :
- shape parameters (ex : Fourier descriptors, shape descriptors, ...),
- a selected part of preprocessed and/or rough data,
- scores (from scoring methods),
- ...
Classification system takes a set of descriptors and/or rough data and evaluates which "class" it should belong to.
One also could say that the output of the Classification system is a qualitative variable with N modalities. Every modality of this variable is called a "class".
There are many Classification techniques such as :
- classical statistics based methods,
- bayesian networks,
- decision trees,
- eigen vectors based discrimination methods,
- artificial neural networks,
- fuzzy decision arrays,
- genetic classifiers,
- vector learning machines,
- expert systems,
- case based reasoning, ...
- ...
Some classification techniques can tune automatically their parameters in order to optimize their performance on a sample of data (we will talk about "supervised learning", even if classical data analysis techniques, for instance, never use such a vocabulary).
Some classification techniques may use the knowledge of experts. We will talk about knowledge based systems.
Postprocessing system allows :
- to estimate the confidence of the classification
- to re evaluate the class taking into account the risk attached to misclassification
- to add a class number (N+1) that says "unrecognized"
The most frequently asked question is "how to build an efficient pattern recognition system ?".
Because the "heart" of such a recognition pattern system is the "classification" system, one often considers that the first task is to choose a classification technique : "should i use neural networks ? Bayesian networks, ...".
This is the wrong way.
The first task is to choose a global architecture : if one uses heavy preprocessings and smart descriptors extractions, classification may become easier. On the opposite, classification from rough data may need to choose a powerful classification technique. The balance between preprocessings, descriptors extraction, and classification complexity is the first point to check. There doesn't exist a unique solution : many solutions may lead to acceptable results.
There is a methodology that helps to build efficient solutions and to evaluate their viability before the development : the AGENDA methodology (see further and check references).
How to build an efficient pattern recognition application : the AGENDA methodology
The AGENDA methodology proposes to write a functional analysis of the pattern regognition system (before starting any development). From this functional analysis, one can choose technical solutions, linking every technical choice to a functional need. This "classical" way of working (classical for regular industrial projects ... but not for pattern recognition projects) allows :
- to share the knowledge of several experts on the rough data
- to choose functional options before any technical choice that could disable a functionality
- to brainstorm on algorithms choice
- to guarantee traceability of every technical choice
- to re use solutions from a project to another if some functionalities are the same
- to test separately every module
- to help for maintenance and further evolutions development
- to communicate quickly with other searchers and engineers (every choice has an explicit reason)
AGENDA proposes a special way of describing functionalities for a pattern recognition system. This way is general and can be applied to a big range of applications. The idea is to consider the known causes of variations of the input vector :
example : character recognition : Known causes of variations are :
- small rotation of the character
- translation
- thickness of lines
- style (font)
- colour of printing
- name of the character (1, a, 2, b, c, ...)
- ...
This causes of variations generate together a combination of cases that leads to a very big number of different characters. That is why pattern recognition is a complicated task : only a few causes of the input vector variations should lead to a variation of the output (ex : name of the character), most causes of variations of the input vector shouldn't change the output (ex : thickness, rotation, translation, ...)
It means that the pattern recognition system can be seen as a "filter" on factors of variations.
This leads to a very simple way of describing the expected functionalities of a pattern recognition system : one should just choose if a factor is to be filtered or not : example :
- small rotation of the character
- translation
- thickness of lines
- style (font)
- colour of printing
- name of the character (1, a, 2, b, c, ...)
- ...
means "usefull" factor of variation : "not to be
filtered"means
"to be filtered"And every
factor should be linked to a technical solution
"invariant with this
cause of variation".Example :
Red links are a memory of the goal of every technical choice.
If one cannot find a solution for some factors of variations, then one still can use a "learning" classification system : example :
It becomes obvious, looking at such an "AGENDA graph", that there exist many solutions : many technical items may have the same "unvariant with" functionality; other sensors may lead to a simpler solution; ...
But this AGENDA Graph can also bring more information :
- every link has a cost : computing time, ...
- intuitively, one can understand that a graph with every link pointing to the classification learning system would need more examples to get tuned than the above graph (example : no preprocessing, no descriptors extraction, and rough data directly into a neural network ...). The idea is to use the design plans in order to build the data base : orthogonal design plans (of the set of factors that point on the learning system) should be considered as a simple way of building this data base.This data base is needed for :
- getting a learning data base (if classification is automatically tuned from data) or a tuning data base (if classification is tuned
by hand),
- getting a test data base : to evaluate performance of the classification system on examples that were not used to tune it.
Although there is a deterministic and simple way of building a relevant data base, one needs to cut this data base into 2 parts in order to get two sub-data bases : the learning and the test ones. This is made by using two fractional sub design plans.
Then, it is important to verify that the 2 data bases are representations of the same statistical phenomenon in the variables space (preprocessed data and descriptors) : mean values, standard deviations, and N first eigen vectors must be the same.
At this point, a classification technique is carefully picked. Criteria of choice are :
- do i have an explicit expertise for classifying examples (is yes, knowledge based systems such as fuzzy decision arrays may be a good solution : they are usually tuned "by hand"; if not, learning based methods, automatically tuned from data, such as neural networks or bayesian networks may be a good solution).
- do i need an explicit explanation of the result (if yes, "black boxes" methods are forbidden ...),
- do i have a software that lets me apply classification techniques (or can i buy one ? develop one ? ...),
There are often several classification techniques that fit into criteria and it is a good thing to test several approches in order to know which part of the result is a "method" effect.
Once the classification system is tuned, it is time to build the post processing system : th aim of this system is to interpret quantitative partial informations of the classification system in order to give to the final result a confidence. Lack of confidence should lead to a new output (never given by a classification system) : "unknown" or "unrecognized".
Methods for confidence estimation are different for every classification method, but main ideas are :
- choose a measure of confidence for the selected class,
- choose a measure of hesitation (comparing confidence for the selected class to confidence for the other classes)
- use a decision method from this measures.
Once the pattern recognition system is available, tests often show cases of misclassification. Analysis of those cases allows to upgrade AGENDA graphs : some factors of variations are added, new preprocessings/descriptors can be picked, and the data base can be upgraded.
This incremental way of building the system is a guaranty of maintenability : indeed, industrial applications often need evolutions among time (new functionalities, new classes, ...). The AGENDA graphs can be considered then as a memory of the engineering process, allowing a very quick reverse engineering for maintenance and upgrades.
For
more questions or applications,
please feel free to contact
us